https://arxiv.org/abs/2308.02223
ESRL: Efficient Sampling-based Reinforcement Learning for Sequence Generation
论文的核心贡献主要包括两方面:
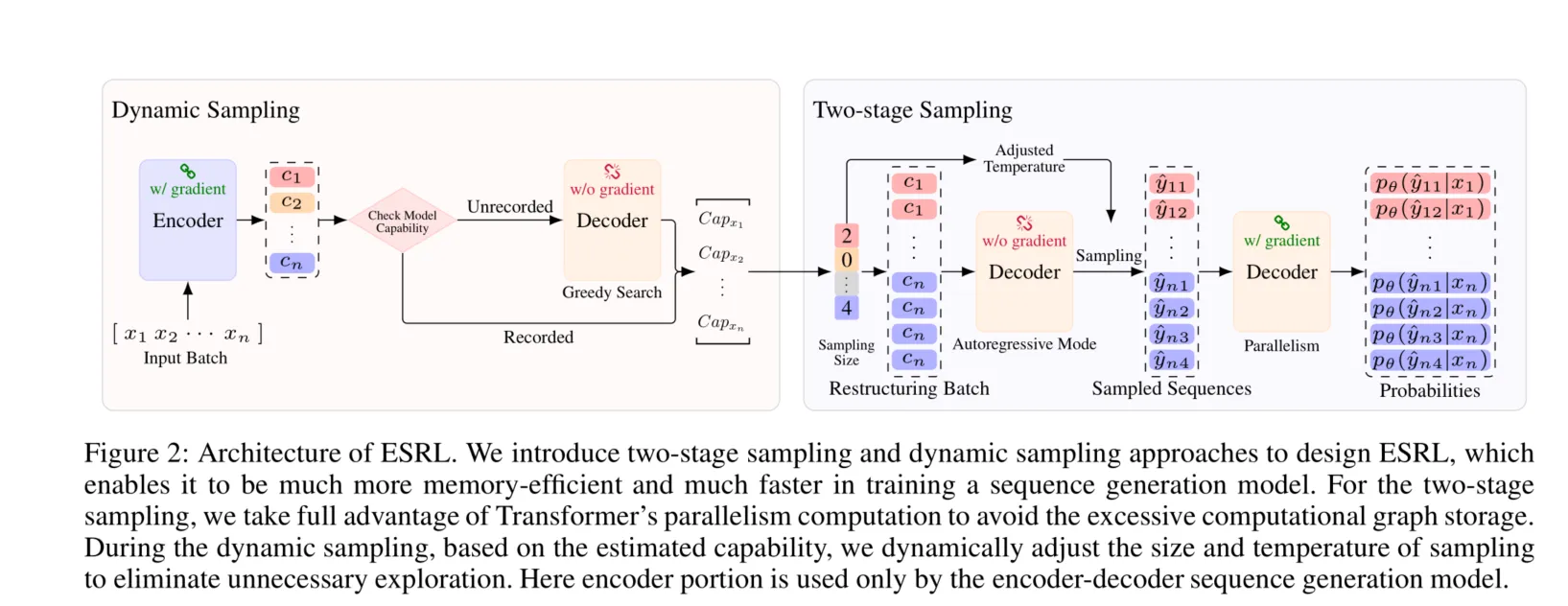
两阶段采样:传统的RL训练在序列生成任务中通常需要为每个生成的候选序列存储计算图,而这会消耗大量内存。为了优化这一点,ESRL采用了两阶段采样方法:在第一阶段,模型采用自回归方式生成候选序列,但不进行反向传播,避免了计算图的存储。第二阶段是计算这些候选序列的概率,利用Transformer的并行计算能力减少了计算图存储的需求。尽管增加了计算时间,但减少了内存消耗。
动态采样:ESRL还引入了动态采样机制,通过估计模型的能力(例如使用BLEU或熵值等度量)来调整采样的大小和温度。具体来说,当模型的能力较强时,减少采样数量;而当能力较弱时,增加采样量以提高探索效果。通过这种方法,ESRL避免了过度采样,从而进一步提高了训练效率。
一切都在此图中,以往模型的采样没有技巧,花费显存和时间,ESRL让这个过程变得高效:
https://arxiv.org/abs/2411.10323
摘要
最近发布的Claude 3.5计算机使用模型脱颖而出,成为首个在公开测试版中提供计算机使用功能的图形用户界面(GUI)代理。作为一个早期测试版,其在复杂的现实环境中的能力仍然未知。在这项探索Claude 3.5计算机使用的案例研究中,我们精心设计并组织了一系列跨越多个领域和软件的任务。通过这些案例的观察,我们展示了Claude 3.5计算机使用在从语言到桌面操作的端到端能力上的前所未有的表现。与此同时,我们还提供了一个开箱即用的代理框架,方便用户部署基于API的GUI自动化模型并轻松实现。本案例研究旨在展示Claude 3.5计算机使用的能力和局限性的基础工作,并通过详细的分析提出关于规划、行动和批判的问题,这些问题必须考虑在内以推动未来的改进。我们希望这项初步探索能激发未来在GUI代理领域的研究。本文中的所有测试案例可以通过以下项目进行尝试:https://github.com/showlab/computer_use_ootb 。
个人总结
LLaVA-o1把问题的回答拆解为这四个阶段:
- 总结阶段:简要概述问题和任务
- 描述阶段:详细描述图像中的相关部分
- 推理阶段:系统化地分析问题并进行推理
- 结论阶段:给出最终答案
https://arxiv.org/html/2406.12793v1
ChatGPT和GLM系列模型的发展
ChatGPT展现了卓越的能力,其最初在2022年11月由GPT-3.5模型[25]驱动,后来在2023年3月升级为GPT-4[27]。根据OpenAI的说法,GPT-3.5系列通过整合指令调优、监督微调(SFT)和/或来自人类反馈的强化学习(RLHF)[28],在GPT-3的基础上进行了改进。最初的GPT-3在2020年发布[3],标志着从GPT-1的1.17亿参数和GPT-2的15亿参数大幅提升至1750亿参数。这种规模的提升使GPT-3具备了上下文学习和通用能力,推动了大型语言模型(LLMs)的出现[6; 41]。
https://arxiv.org/abs/2310.11441
SoM(Set-of-Mark)提示是一种新的提示机制,具体来说,就是在图像的不同区域上添加一组视觉标记。通过在输入图像上覆盖数字、字母、掩码或框等各种格式的标记,SoM帮助模型更好地理解和定位图像中的语义上有意义的区域。这样做的目的是增强模型在视觉内容上的定位能力,使其能够更准确地将答案与相应的图像区域关联起来。
也就是改了图的。
https://arxiv.org/abs/2401.01614
摘要
最近在大型多模态模型(LMMs)上的发展,尤其是GPT-4V(ision)和Gemini,迅速扩展了多模态模型的能力边界,超越了传统任务如图像字幕生成和视觉问答。在这项研究中,我们探讨了像GPT-4V这样的LMMs作为通用网络代理的潜力,该代理可以遵循自然语言指令在任何给定网站上完成任务。我们提出了SEE ACT,这是一种通用的网络代理,利用LMMs的力量在网络上进行集成的视觉理解和操作。我们在最近的MIND2WEB基准上进行了评估。除了在缓存网站上的标准离线评估外,我们还开发了一种工具,使得能够在在线网站上运行网络代理的新在线评估设置成为可能。我们展示了GPT-4V在网络代理方面的巨大潜力——如果我们手动将其文本计划落实为网站上的动作,它可以成功完成51.1%的在线网站任务。这大大优于文本仅限于LLMs如GPT-4或专门为网络代理微调的小型模型(FLAN-T5和BLIP-2)。然而,落实仍然是一个主要的挑战。现有的LMM落实策略,如标记集合提示,事实证明对网络代理无效,而我们在本文中开发的最佳落实策略利用了HTML结构和视觉。然而,与理想的落实相比,仍然存在显著差距,为进一步改进留下了充足的空间。所有代码、数据和评估工具均可在 https://github.com/OSU-NLP-Group/SeeAct 获取。
https://arxiv.org/abs/2201.11903
作者单位:谷歌的研究团队
摘要
我们探讨了如何通过生成一个思维链——一系列中间推理步骤——显著提高大型语言模型执行复杂推理的能力。尤其是,我们展示了在足够大的语言模型中,这种推理能力如何通过一种简单的方法自然地涌现,这种方法称为思维链提示(chain-of-thought prompting),其中提供少量的思维链示例作为提示中的范例。
在三个大型语言模型上的实验表明,思维链提示在一系列算术、常识和符号推理任务上提高了性能。实证收益可能非常显著。例如,仅用八个思维链示例提示一个PaLM 540B模型,就能在数学文字题的GSM8K基准测试中达到最新的准确性,甚至超过了经过微调并带有验证器的GPT-3。
https://arxiv.org/abs/2210.03629
作者单位:
普林斯顿大学计算机科学系 谷歌研究,大脑团队
个人总结
模型回答问题,我们当然期望是由问题直接映射到回答,这需要太多先验数据集训练,在世界上你总能找到问题是没出现在训练集的。这时候就需要一些策略让模型变得聪明一点,而类似CoT,或者本文的ReAct ,就是在试图让大模型变得会思考问题,人思考一个问题有可能会发散,比如问题是"你是人吗",那么人的大脑直接回答"我是人",那如果问题是"腾讯投资的前个公司叫啥名",人就会借助工具开始发散了。
一些复杂问题或者密集问题,人都需要发散思考,然后得到答案,而解决问题的途径,正是这些框架想做的事情。
Android Instruct 数据集,该数据集包含 94.3k 条操作记录,用于细调模型。
A NDROID L AB 基准测试提出了显著的挑战,因为即使是领先的模型 GPT-4o 也只能达到 31.16% 的成功率。
ANDROID L AB 定义了一组动作空间和两种操作模式,形成了 ANDROID L AB 环境。我们采用了前人工作中的主要动作空间,并增加了一个模型返回值(完成动作)。这两种基本的操作模式是 SoM(Yang et al., 2023a)和仅 XML 模式,区别在于代理是否可以访问手机屏幕的快照。
拉:
bash展开代码docker pull ollama/ollama
运行
bash展开代码docker run -d --rm -p 11434:11434 --gpus device=3 \
-v /ssd/xiedong/openwebui-test/ollama:/root/.ollama \
--name ollama ollama/ollama
docker run -d --rm -p 11435:11434 --gpus device=2 \
-v /ssd/xiedong/openwebui-test/ollama:/root/.ollama \
--name ollama2 ollama/ollama
进容器:
展开代码docker exec -it ollama bash docker exec -it ollama2 bash
退出容器就嘎了,我直接tmux:
bash展开代码apt update && apt install -y tmux
运行模型:
bash展开代码ollama run qwen2.5:72b-instruct ollama run qwen2.5:32b-instruct
拉:
bash展开代码docker pull ollama/ollama
运行
bash展开代码docker run -d --rm -p 11434:11434 --gpus device=3 \
-v /ssd/xiedong/openwebui-test/ollama:/root/.ollama \
--name ollama ollama/ollama
进容器:
展开代码docker exec -it ollama bash
运行模型:
bash展开代码ollama run qwen2.5-coder:32b
退出容器就嘎了,我直接tmux:
bash展开代码apt update && apt install -y tmux
前言
gpt或者别的大模型,在openwebui里使用起来很难受,因为没有编排技术。
何为编排技术?:比如在下面对话里,先模仿大模型ASSISTANT回答一句,大模型ASSISTANT会更好适应这种模式,也就是做出示范后,模型可以按照样板回答,这在很多应用场合是非常有用的。
展开代码USER:无论我说什么,你都说你是小明。 ASSISTANT:我是小明。 USER:你是谁?
https://arxiv.org/abs/2405.20797
https://github.com/AIDC-AI/Ovis
国内下载预训练模型快捷方式:
bash展开代码conda create -n modelscope python=3.10
conda activate modelscope
pip install modelscope
modelscope download --model 'AIDC-AI/Ovis1.6-Gemma2-9B' --local_dir '/data/xiedong/AIDC-AI/Ovis1.6-Gemma2-9B'
纯英文模型,不是中英文模型,算法,不调了:

目的
大家都在玩app-agents,一个统一的android操作框架和评估方法是被需要的,这篇论文开源了他们的框架,名为AndroidLab。
